
When creating the 3DS and Switch versions of OutRun, developer M2 added a number of new music tracks. Thankfully, most adhered to the original Music Macro Language (MML) format used by the original game. Once extracted from the 3DS, the music data plays out of the box on original hardware, with minimal modifications to the Z80 program code. Delightful dedication on behalf of the composers.
Unfortunately, as mentioned in the previous blog post, the file size of this new music is substantially larger than the original music. As a comparison, the new tracks weigh in at around 3-4 times the size.
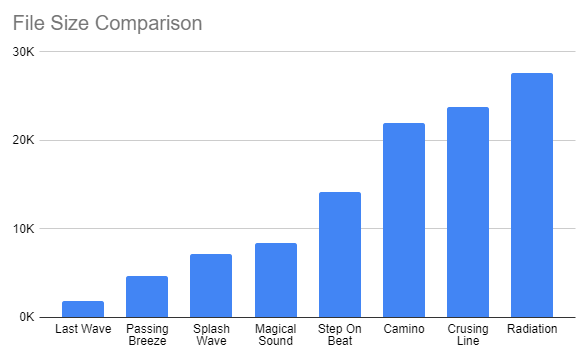
This isn’t a result of additional length or musical complexity. File size is simply not a concern on modern hardware. However, my dream is to add multiple music tracks to a future release of OutRun Enhanced Edition. This relies on the hope that they could be reduced in size and programmed back to the original arcade PCB, without the need for additional hardware. As such, I’ve spent my evenings studying and optimizing the first OutRun 3DS tune: Camino a Mi Amor.



The original music was composed by Hiro on a Roland MC-500 keyboard and transcribed as sheet music, before being hand translated to MML. This ensured the original MML was well structured and highly optimized. After coding an MML decompiler, I could study the new music and determine why there is a size disparity, and more importantly recompile any optimizations back into the OutRun audio engine.
It was clear that the new MML data was auto-generated by some kind of tooling. I believe that the new audio was composed in a modern Digital Audio Workstation package (DAW) and then run through a conversion process for reasons I’ll outline below.
1/ The music is incoherently structured.
One of the powers of Sega’s Music Macro Language is the ability to use nested loops and subroutines. When used wisely, these radically reduce data duplication and therefore save a lot of space. Music is inherently repetitive, especially when divided into individual channels of audio. When studying Camino, it’s apparent the subroutines have been automatically generated, rather than created by hand. Rather than a subroutine containing a musical pattern that make sense in isolation, subroutines frequently start and end at illogical points from a composition perspective. Many of the subroutines are called just twice whereas you’d expect, especially with repetitive channels containing drum patterns, a much greater degree of reuse.
M2 were on point for writing tooling to identify repeated sections of data. Theoretically, it’s a smarter, faster approach than attempting to optimize by hand. However, it’s a difficult problem to solve well and the results are only as good as the algorithm. And in this case, the results are mediocre. Aside from badly structured subroutines, the tooling created subroutines that are called just once, rendering them pointless. And furthermore they’d overlooked a separate problem further up their toolchain...
2/ The music does not adhere to the inherent timings of the audio engine.
As Cmonkey explained in his documentation: the overall tempo of the tune is controlled by timer A on the Yamaha 2151 sound chip. This timer is loaded with a value of 524 during initialisation of the audio engine. The calculation used for the timer A period (in ms) is:
tA = 64 * (1024 - tAvalue) / input clock (KHz)
The sound chip has an input clock of 4 MHz (4000 KHz). So this means the timer A period is calculated as:
64 * (1024 - 524) / 4000 = 8ms
So, to play a note for 1 second, you'd pass a value of 125 as the duration (125 * 8ms = 1000ms = 1s).
Now, where Camino a Mi Amor falls foul of this system is that its core timing is not divisible by units of 8ms. As such the music is quantized to fit the audio engine’s timing, ensuring the notes align to 8ms boundaries. Let’s look at a typical sequence of notes to clarify this point. This series of commands simply plays the note D at octave 4 a number of times with a few rests thrown in for good measure.
So far so good. However, the second time this sequence is exported from the DAW to MML, there are subtle timing differences:
- The first version of this sequence plays D4 for a length of 57, which is 456ms (57 * 8).
- However, the second version of this sequence plays D4 for a length of 58, which is 464ms (58 * 8).
- This disparity is offset by the second use of D4 in the sequence, where the timing is inverted.
Both versions of the sequence last the same total duration, but the notes are aligned differently. Imagine the original composer setting a chosen tempo in his audio software. When the exporter reached the second version of the sequence, it was quantized to the closest possible duration, in order to work with the default audio engine timing. The second time round, the quantization was applied to different notes in the sequence. The difference is inaudible to the ear and, in fact, an artefact of M2’s tooling, rather than a deliberate artistic choice. The timing differences also affect the drum patterns, which you would expect to be rigid, rather than variable. It should also be noted that the timing differences are only ever +/- 1. Any additional difference would be an artistic choice. To compound the problem, the tooling inserts additional ‘REST 1’ commands in various sequences to compensate for the timing differences, which wastes further space.
For file size, this is a critical problem. Each version of the sequence is now treated as a separate block of data, rather than a shared subroutine. It’s effectively different from a data perspective, despite sounding identical. This is part of the reason the previously described subroutine automation is a failure. It is fed imperfect data to process and cannot identify sections of the audio that should be identical. Whilst my example shows just two versions of the same sequence, in reality there are often many more. This is incredibly wasteful, as well as making the resultant MML unwieldy.
We’re faced with bulky MML, littered with illogical subroutines, that needs a major restructure to wrestle it into shape. I tackled the problem by listening to each channel of audio in isolation and capturing it to a waveform. This helped build a mental and visual image of the structure of the music channel. The next part of the process wasn’t an exact science, but I started visually identifying chunks of MML data that looked similar, unrolling subroutines where necessary. I built a Google Sheet that would help me do this.

I could simply copy and paste two giant blocks of MML data that I suspected were identical into the sheet. The sheet formulae would verify the list of commands were in fact identical, verify the timing of each command didn’t differ by more than +/-1 timing unit and finally sanity check that the overall timing of the block was identical. Once happy, I could return to the MML, remove the obfuscated original data and subroutines and move them to a shiny clean subroutine.
Effectively, I was consolidating all of the data variations back into a coherent section of music. Some of these could be reused multiple times, which was a huge optimization. If you think back to the previous example with two versions of the same sequence, there is no reason both of these sequences shouldn’t be identical, as long as the overall timing of the block is the same. The upside to this, is that we’re returning to the vintage 1986 Hiro approach of hand-crafting MML. We can make genuine use of powerful loops and smartly organised subroutines.
I’ve made this process sound a breeze, but in reality it was time consuming and error prone. With over 10,000 lines of MML data to work with for the first track alone, one small error could throw the timing of the entire tune, especially if the error was contained in a loop that was iterated over multiple times. I found I could manage 2 to 3 hours of this work at a time, before needing to call it quits. Despite that, it is an incredibly fun puzzle to crack. My score was the byte count. Every time I hit recompile, my savings were output to the console. The lower the score the better I felt. Sometimes I needed to increase the overall size in the short-term as a strategy to reduce it considerably in the long-term. I’m unsure whether this process could be automated to produce MML that was as clean. Maybe it could and I just don’t want to admit it. Certainly, it would be easier to improve M2’s tooling to create better MML in the first place, if I had access to it.
3/ Cross channel optimizations are missed.
Wait, we’re not done yet! There were other easy trends to spot. For example, FM channel 0 and FM channel 1 shared a bunch of note data. I suspect the conversion tooling did not work across channels. It was trivial to move this into its own subroutine.
4/ The REST command is everywhere!
For FM channels, the REST command largely serves a purpose. It’s akin to depressing the note you’re playing. However, for percussion channels it serves less of a purpose. Consider the following sequence of commands:
KICK_DRUM 42
REST 10
KICK_DRUM 14
This translates to:
- Play the kick drum sample. Wait 336ms (42*8).
- Rest for 80ms (10*8).
- Play the next kick drum in the sequence.
The technicality to note is that once a sample is initiated, it can only be interrupted by another sample. The REST command adds little value, beyond inserting a delay before the next command. Therefore, the above block can be optimized to:
KICK_DRUM 52
KICK_DRUM 14
We’ve shaved 2 bytes from this 6 byte sequence! This might not sound much in isolation, but when the command is littered across all percussion channels, you can claw back a considerable number of bytes and save Z80 cycles in the process.
Generally speaking, for FM channels the REST command should be left well alone. Removing REST commands would change the way notes sustain and decay. However, there are exceptions to this rule. Earlier, I mentioned M2’s tooling had inserted ‘REST 1’ commands in the FM channels to compensate for audio timing differences. This was particularly obvious when comparing two identical blocks. One might look like this:
F4 14
REST 1
F4 28
REST 14
The second might look like this:
F4 15
F4 28
REST 14
The first block adds an 8ms rest between the two F4 notes. The second block adds the delay to the time the note is played for and does away with the REST command entirely. Therefore, both versions could be condensed into the succinct second version. This optimization might appear to be a leap of faith, but it does become apparent as artefact removal when analyzing 10,000 lines of MML by hand! I studied both variations in a wave editor and found no visual difference, let alone an audible one. In reality the block would be longer than the example provided of course.
5/ Patches and Erroneous commands.
My MML decompiler performs other handy analysis. For example, it denotes which FM patches (or FM sounds if you like) are in use by the track. The unused patches can quickly be removed by hand. Furthermore, the MML contained junk data. For example you’d see command sequences as follows:
LOAD_PATCH 6
REST 10
LOAD_PATCH 16
C4 10
Clearly the initial LOAD_PATCH command is trumped by the second and can be removed. There's no need to load the first sound patch, as no notes are played! There were other examples of redundant commands that also provided a small but welcome saving.
In Conclusion
In total, the above methods sliced a whopping 10k from the original track - a saving of 46% - with hopefully no loss of musical integrity! But this hard work is only just the beginning, and soon I'll need to tackle the next track - Cruising Line.
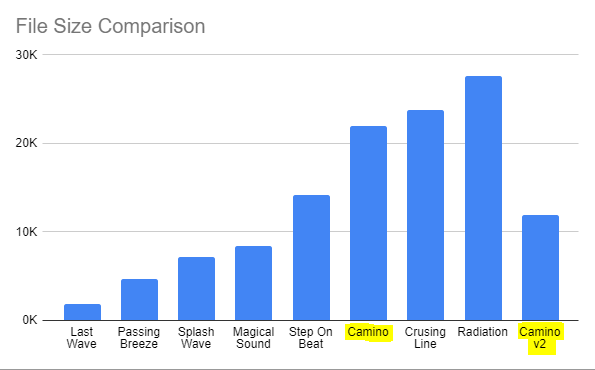
Parting Words
I’m frequently asked if a feature or idea is possible. Can something be done? Couldn’t you just…? And the answer is often theoretically yes. Yes, if you’re prepared to pour time and energy into seeing a hair-brained scheme through to fruition. Of course, you could, and maybe should, view this entire process as complete madness. All this effort to trim mere bytes from a binary file: reversing the MML format, cmonkey’s robust tooling to create and compile MML files, the decompiler to reverse 3DS binaries back into an editable format, countless evenings spent manually manipulating data with a hodgepodge of makeshift tools. And we’re nowhere near done yet, but let’s keep going, because no one else will!
6 comments:
Thank you for working on it ;)
WahWah
If only I could help you, I would...
Thx so much Chris !
I wonder, do you think that the sound patches could be exported as a system exclusive for an FM synth or VSTi.
Great work!
@roblive2007: Yes they could. You'd need a simple conversion script, or to do it by hand. I've converted an OPM patch back to the OutRun engine. But more of that in a future blog post.
Is "Camino a Mi Amor" in 7/4 time (or some variation like 4/4 + 3/4)? It seems to be from listening to it, and your table of note lengths totals 199 time units with the shortest duration being 14 or 15 units long. If you divide 199 by 7 you get about 28.4. Half that is about 14.2, and twice it is about 56.9. So I would expect to see 56/57 for the longest duration, not 57/58, and 28/29 for the second-longest note rather than 27/28.
Either way, I'd probably go as far as re-quantizing all measures to 196 units, so all durations would be exactly 14, 28, or 56 units long. This would slightly increase the tempo from 132 to 134, though I doubt anyone would notice that. Having fewer possible note lengths might also give you more opportunities for sequence reuse (and a smaller file size).
Post a Comment